1 Internal or External?
I categorize the errors into two types, one is originated from the internal pages, another is from external websites. For normal linking error from internal pages, if you make a mistake, then edit to fix it. Simply as that.
But some can’t be fixed easily, like those not-actual-URL in JavaScript incorrectly detected by Googlebot or total craps from external craps. The following screenshot shows these two, above and below the red line, respectively.
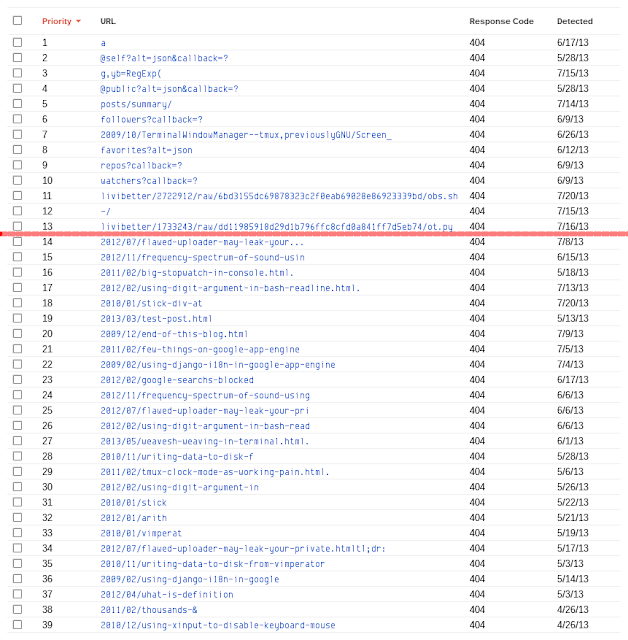
[style edited to fit all entries into one screenshot]
This was taken from the report for this blog. 39 entries across roughly 3 months, in other words, three months and I had got these errors which only three of them were actual errors.
2 In JavaScript
Googlebot loves reading your JavaScript code. From Unexpected 404 errors, it explains why Googlebot sees URLs that we don’t see with an example HTML code:
<a href="helloworld.pdf" onClick="_gaq.push(['_trackPageview', '/download-helloworld']);" > Hello World PDF</a>When it sees this, as an example, Googlebot may try to crawl the URL http://www.example.com/download-helloworld, even though it’s not a real page. In this case, the link may appear as a 404 (Not Found) error in the Crawl Errors feature in Webmaster Tools.
Although it also says that it’s safe to ignore when we are sure that Googlebot is just link-happy bot, but it’s still annoying and they might stick around forever if nobody is taking action on it. I did mark them as fixed, but they show up again later on, so it’s time to obscure the JavaScript code.
The following diff shows how I get around the issue:
diff -r 2a2a78f8fb44 -r 7018dd22c522 yjlv/page/Search.html --- a/yjlv/page/Search.html Wed Jul 24 09:29:25 2013 +0800 +++ b/yjlv/page/Search.html Wed Jul 24 09:34:36 2013 +0800 @@ -221,7 +221,7 @@ } var labels_part = labels.join('/'); if (labels_part) - labels_part = '/-/' + labels_part; + labels_part = '/' + '-/' + labels_part; var query_url = $('#search-blog-url').val() + "feeds/posts/summary" + labels_part; var kw = { alt: 'json-in-script', diff -r 2a2a78f8fb44 -r 7018dd22c522 yjlv/post/2010/YouTube Favorites simple search.html --- a/yjlv/post/2010/YouTube Favorites simple search.html Wed Jul 24 09:29:25 2013 +0800 +++ b/yjlv/post/2010/YouTube Favorites simple search.html Wed Jul 24 09:34:36 2013 +0800 @@ -66,7 +66,7 @@ var n = Number($('#yt-fav-n').val()) || 0; // Let YouTube to decide var index = (parseInt($('#yt-fav-page').val()) - 1) * n + 1; var query = (q ? '&q=' + encodeURIComponent(q) : '') + (n ? '&max-results=' + n : '') + '&start-index=' + index; - var url = search_base + username + '/favorites?alt=json' + query + '&callback=?'; + var url = search_base + username + '/' + 'favorites?alt=json' + query + '&callback=?'; $.getJSON(url, yt_fav_render); }
Frankly, using '/foobar' pattern to detect is just a piece of terrible code by Google. Using external API is very common, data often come from external source. For different API code, you have different endpoint, and it’s not uncommon to separate as base_URL + method + ....
When you have this kind of error, you need to separate / character from the string and re-code it as '/' + 'foobar'. This is so pathetic, I must say as a coder. Someone builds a flawed thing, and you apply a ridiculous thing just to have some sort of peace.
For some time, I always thought Googlebot did evaluate JavaScript, but apparently it didn’t, it only extracts from strings of code. I gave too much credit to Google and Googlebot, they weren’t that awesome.
3 External craps
For the entries caused by external websites, there is really not much you can do about it if you don’t have control of the external websites.
There are plenty of crappy websites. The crappiest websites to my blog are those scrapping Stack Overflow. Some of my blog posts got referred by Stack Overflow questions, therefore also by those crappy websites. In the first screenshot, you can see many post slugs got cut off mysteriously. For a long time, I really couldn’t figure out why until I finally clicked on one of the websites to check out the HTML code.
The screenshot below tells the whole story of how those cutoff occurs.
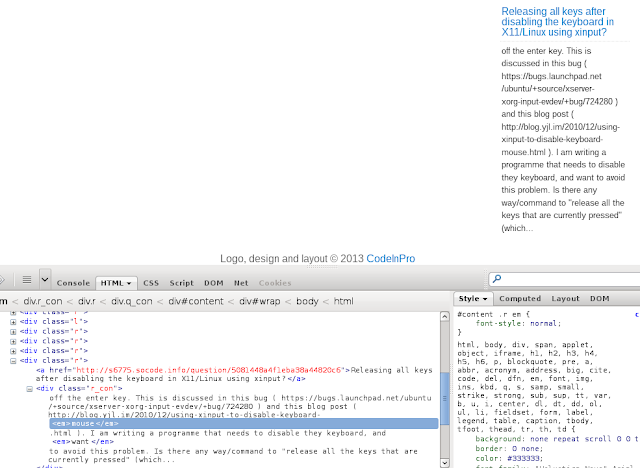
For some reason, the <em> doesn’t provide any visual effect to the visitor, don’t you feel strange? You can see the website even overrode the font-style in bottom-right style tab. That makes me think such tag is added on purpose to disrupt Googlebot’s URL detection, so it would show up in 404 error report.
So, what can you do with it?
Nothing much, just select all and mark them as fixed. Hopefully, Googlebot doesn’t go back to those pages or the mention to my blog post will fall out of that sidebar.
Nonetheless, from this we have learned that if someone write http://my.example.com/something outside of your website, even in text nodes, Googlebot will pick it up and think it’s a URL to check up.
4 Conclusion
Fix them or mark them as fixed, or just pretend nothing is there.
Google needs to provide more control on Crawl Errors report, because I truly believe some are abusing it by faking as described in external craps. You may think that’s too much work, but the reality is spammers do this kind dirty things a lot, they exploit everything they can find, even your granny’s Facebook page. They don’t have morality.
Also, Googlebot needs to be smarter. Regular expression doesn’t cut it.
The accuracy of Crawl Errors is extremely low. As matter of a fact, three were only true errors, two of which were mistakes by GitHub on their Gist embed, they accidentally use my blog’s host name as Gist’s host name, and it’s already fixed after I contacted them. Only #7 was my fault. The rest are incorrectly detected or from craps, all false positive errors.
Speaking in numbers, 3 out of 39 over 3-month period, that’s only 7.69% accuracy and this is Google who made this report. If we count what’s only my fault, then that’s only 2.56%, only 1 error that I could actually do something about and probably is only case or error I do care.
When you’re 404-linked, you’ve got nothing. No traffic, no credit, no link-in history.
You’re stuck in whatever report they decide to throw you with. “Where am I?” “NOTFOUND.”
You do whatever fix comes your way.
You rely on anyone who’s still going to you.
A link-happy Googlebot; “Should we check them?”
0 comments:
Post a Comment
Note: Only a member of this blog may post a comment.